Sol: Multi-Agent Orchestration That Recovers From the 2 AM Crash

If you've used AI coding agents (Claude, Codex, or similar) you know the pitch: describe the work, let the agent build it. But at some point you think, "if one agent can handle one task, why not run five at once?"
I've been running multiple AI agents in parallel against real repositories for a while now. Not as an experiment, as my actual workflow. And I kept hitting the same problems: sessions crash at 2 AM and nobody notices, agents edit the same files and create merge conflicts, finished work piles up in branches that nobody merges, and I spend more time babysitting than building.
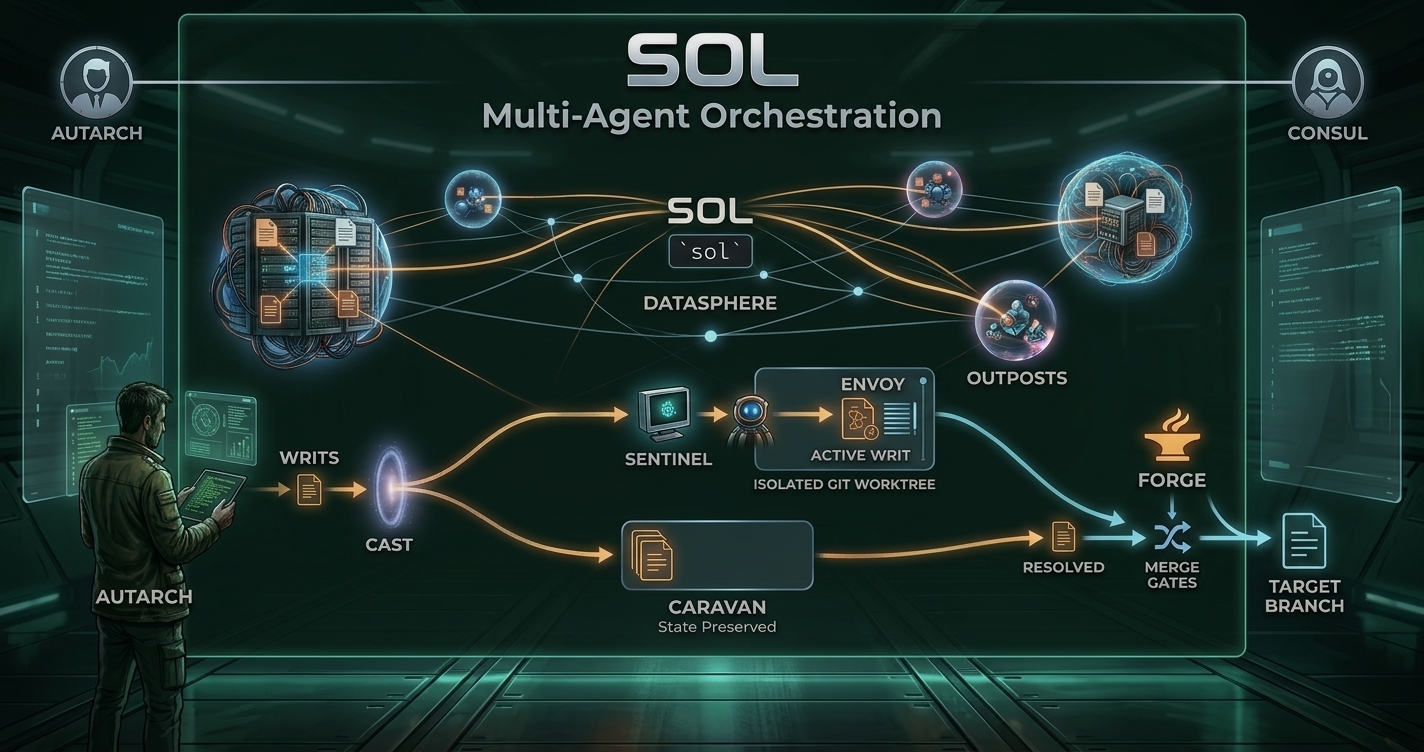
I built Sol to fix those problems. It's one Go binary that coordinates concurrent AI coding agents working on a shared repository. Each agent gets its own isolated git worktree, a persistent assignment that survives crashes, and a supervisor that restarts failed sessions. Completed work flows through a merge queue with quality gates before landing on the target branch. SQLite for state, tmux for sessions, plain files for assignments. No containers, no servers, no cloud dependencies.
The Inspiration
Steve Yegge's Gas Town proved that this kind of system is possible. After playing with it, I found myself wanting something more reliable, something that would let me do a pile of design work to spec out a feature and then let the coding agents run with it without me needing to babysit their operation. Gas Town demonstrated the core concepts: persistent agent identities, git worktree isolation, crash-durable assignments, a merge queue. It's a good prototype. Sol takes those ideas and tries to make them work reliably for me.
A quick note on the naming: when you're building a system with this many moving parts, you need coherent nomenclature that the AI agents themselves can keep straight. I landed on a space-faring civilization theme (worlds, outposts, envoys, caravans, the forge) and it's stuck well enough that I haven't had a reason to change it. Once you learn the handful of terms, the CLI reads naturally. Please forgive the theme.
How It Works
A world is a repository under management. You point Sol at a repo, and it clones it, sets up a database, and gets ready to accept work. Work is described as writs, units of work with a title, description, and status. When you cast a writ, Sol assigns it to an agent, creates an isolated git worktree branched from the target, and starts a Claude session. I have a Codex adapter in progress as well. I mostly use Claude at the moment, but I wanted the ability to swap.
The assignment is written to a tether, a plain file on disk that describes what the agent is supposed to do. This is the critical durability primitive. If the agent's session crashes, the tether survives. When the session restarts, the agent reads its tether and picks up where it left off. It doesn't know it crashed. It just sees work to do and gets to it.
When an agent finishes, it calls sol resolve, which pushes its branch, creates a merge request, and clears the tether. The forge, Sol's merge pipeline, picks up the branch and runs it through quality gates before merging into the target branch. No untested code lands automatically.
What Breaks and How It Recovers
I spent a lot of time on failure modes because that's where most multi-agent setups fall apart. When you're running agents overnight, you need the system to keep working when things go wrong.
Every component in Sol has a defined crash recovery path. The core invariant: an agent with work on its tether and a local worktree needs nothing else to execute. The entire coordination layer can be down and in-flight work continues. Recovery happens when services return.
If Sol itself crashes, agents keep running independently in their tmux sessions. If the merge queue goes down, completed branches wait safely. If the database has a hiccup, agents with tethered work continue executing. The system degrades gracefully instead of cascading failures.
A supervision hierarchy keeps things running:
- Prefect: the top-level orchestrator. Monitors all processes, restarts anything that dies.
- Sentinel: per-world health monitor. Detects stalled agents, crashed sessions, zombie processes.
- Forge: the merge pipeline. Runs quality gates on completed branches.
- Consul: system-level patrol. Cleans up stale assignments, auto-dispatches queued work.
When three or more agents crash within 30 seconds, the prefect enters degraded mode. It stops respawning and notifies you. This prevents a cascade where a systemic issue (bad git state, full disk) causes continuous crash-restart loops.
My Workflow
Here's what my day-to-day looks like:
-
Plan. I maintain an AI-specific branch that Sol agents work against. I have a persistent planner agent (what Sol calls an envoy) that I use as a design partner to spec out the work: what needs to be built, in what order, what the acceptance criteria are.
-
Organize. Related writs get grouped into a caravan with phases grouping work. Each phase waits for the previous to complete before dispatching. Writs can also depend on other writs to complete before they cast. This gives you a multi layer DAG of work that Sol can execute without agents stepping on each other.
-
Commission. Once the plan looks right, I commission the caravan. Sol's consul starts auto-dispatching writs as agents become available and dependencies are satisfied.
-
Review. Agents that crash get restarted. Agents that stall get detected. Completed work gets merged. I check
sol statusperiodically or just check back when things are done. -
PR. When the caravan is done, I create a PR from the AI branch to main and review the aggregate result.
The value is that I can do a thorough job speccing out the work and then walk away. Go make dinner. Sleep. Work on something else. When I come back, either things are done or I have clear information about what went wrong.
Honest Assessment
Sol is at v0.1.0. It works: agents dispatch, execute, and merge real code in my daily use, including iterating on Sol itself. But I won't pretend it's some great piece of software. The API surface isn't stable yet, there are rough edges, error messages in some paths could be better, and documentation is still catching up with the implementation.
It runs agents in YOLO mode (dangerously skip permissions), so you'll want to sandbox it. An isolated VM is my recommendation. The agents have full filesystem access and can run arbitrary commands, which is by design, but it means you should treat the environment as untrusted.
I don't typically make my personal tools public, or have the free time to create things like this. But Sol has been useful enough in my own workflow that I figured someone else might find value in it too. I plan to keep iterating, with an eye towards stable CLI JSON output and webhooks to act as an integration API.
Getting Started
Prerequisites: tmux, git, and an authenticated Claude Code CLI.
# macOS
brew install nevinsm/sol/sol
# Linux: pre-built binaries at GitHub releases
# Or build from source (requires Go 1.24+)
make install
# Check prerequisites
sol doctor
# Initialize (creates ~/sol and your first world)
sol init --name=myproject --source-repo=git@github.com:org/repo.git
# Create and dispatch work
sol writ create --world myproject --title "Implement feature X" \
--description "Description of the work"
sol cast <writ-id> --world myproject
# Watch an agent work
sol session attach sol-myproject-Toast
# See what's happening
sol status myproject
# Start full supervision: health monitoring, auto-merge, crash recovery
sol upSol includes baseline planner and engineer personas as part of agent creation, based on the ones I use daily. Not prescriptive, but a reasonable starting point.
The source and docs are on GitHub: design philosophy, failure modes, CLI reference, operations guide. If you hit problems, open an issue.